Mikio Braun
@mikiobraun
Part of a thread
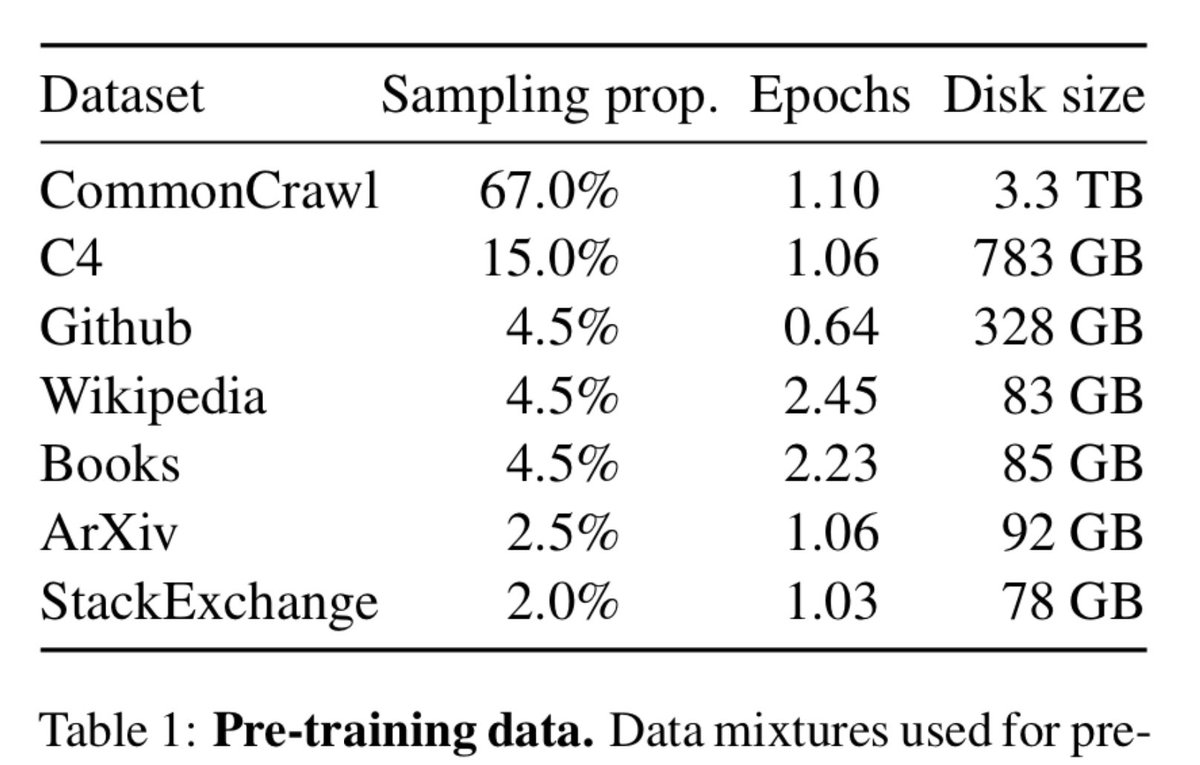
This for example is what meta‘s llama model was pretrained on arxiv.org/abs/2302.13971 Nobody went through all of those 3.3 TB of CommonCrawl data, believe me.
LLaMA: Open and Efficient Foundation Language Models
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and...
arxiv.org
1
Likes